70B LLaMA 2 LLM local inference on metal via llama.cpp on Mac Studio M2 Ultra
TLDR; GPU memory size is key to running large LLMs — Apple Silicon because of its unified memory enables local simulation of enterprise class A100/H100 GPUs (lower speed/bandwidth though) that start at 40GB so one can prep for production model serving on Nvidia GPUs hosted on Google Cloud.

There are several LLMs that are Cloud API accessible like Google LaMDA, GPT-3, DeepMind GATO, Google PaLM — see https://huggingface.co/spaces/optimum/llm-perf-leaderboard — we will concentrate on downloadable models that can be run locally. There are some core models that have been released recently in 2023 including UAE TII Falcon 180B (Sept 2023), Mistral 7B (Sept 2023), LLaMA 2. We will concentrate on the Code LLaMA 2 released by Meta in July 2023
This article is part of a series on preparing for LLM and general ML training/inference on data center class GPUs hosted in the cloud. As I am a traditional java developer that is reentering the data science / ML workspace from the time of Genetic Algorithms (before Deep Learning and Transformers entered the space recently) — working both bottom up from the CUDA/Tensorflow training space and top down running models locally before hosting on CSPs helps with onboarding. I am targeting the audience of developers/architects/devops like myself that wish to enter LLM development as a (currently) non-ML expert. At the moment the most developer friendly method of local LLM inference that requires between 48G and 150G vram is on a single M2 chip. The cost is between 6–12K CAD for Apple Silicon (50 of 64G) to (150 of 192G). The cost for two A6000’s is similar at around 15K CAD for 96G VRAM. Smaller models like the 7B can run ok on base Lenovo P1Gen6 Ada 3500 or Macbook Pro M3 Max as well.
We will be running the originally released Meta LLaMA 2 70B model https://huggingface.co/meta-llama/Llama-2-70b/tree/main (and optionally the Google C4 https://www.tensorflow.org/datasets/catalog/c4 as well in the next series on a dual Nvidia A4500 cluster with combined 40G VRAM in addition to a cluster of Nvidia L4 GPUs on Google Cloud — in the next series as well.
Quickstart
We are grateful for the work of Georgi Gerganov https://github.com/ggerganov and his contributors to llama.cpp for the Apple ARM based LLM enabler.
Prepare your Mac with XCode and XCode command line tools. There is no need yet for CUDA or Python virtual environments yet in this tutorial. We will be running directly on the system and not through the standard docker container method.
Navigate to the llama.cpp repo
git clone https://github.com/ggerganov/llama.cppRun make on the llama.cpp codebase
cd llama.cpp
makeDownload a model that will fit in your unified memory size.
Here we search the the Hugging Face repo specifically for gguf format models derived from the 70B LLaMA model.
The 49G https://huggingface.co/TheBloke/CodeLlama-70B-hf-GGUF/blob/main/codellama-70b-hf.Q5_K_M.gguf
Note that MacOS will allocate between 75–79% of your ram for the GPU
Run inference on the model
./main -m models/codellama-70b-hf.Q5_K_M.gguf -p "factorial function in java 21" -n 400 -eThe 70B model at 46G fits in 64G VRAM (at 51G allocated max)
ggml_metal_init: picking default device: Apple M2 Ultra
...
ggml_metal_init: recommendedMaxWorkingSetSize = 51539.61 MB
ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 160.00 MiB, (46689.55 / 49152.00)Output
Factorial of a non-negative integer, is multiplication of all integers smaller than or equal to n. For example factorial of 3 is 3*2*1 which is 6.
We have discussed how to compute factorial of large numbers using BigInteger in previous post. In this post we will discuss another way to calculate factorial of large number using java program. This method can be used in programming competitions where memory and time are constraints. We need only print the result so it is not necessary to store complete result.
1) Start from leftmost digit, i = 0
2) Find value of (arr[i]*x + carry)%10 and update carry
3) If current digit becomes 0, then delete that digit from array
4) Decrement size
Following is implementation of above idea.
*/
// A function to multiply x with the number represented by arr[].
// This function uses simple school mathematics for multiplication.
// This function may value of result if the input integer has
// more digits
int multiply(int x, vector<int> &arr) {
int carry = 0; // Initialize carry
// One by one multiply n with individual digits of res[]
for (int i=0; i < arr.size(); i++) {
int prod = arr[i] * x + carry;
// Store last digit of 'prod' in res[]
arr[i] = prod % 10;
// Put rest in carry
carry = prod/10;
}
// Put carry in res and increase result size
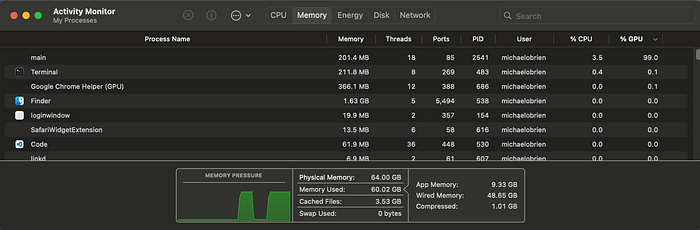
while (carry) { Performance for M2 Ultra 64G 24(16p/4e) core, 60 GPU (base model)
It takes about 30 seconds to fill 49G of VRAM from the NVMe
llama_print_timings: load time = 69713.02 ms
llama_print_timings: sample time = 32.47 ms / 400 runs ( 0.08 ms per token, 12320.20 tokens per second)
llama_print_timings: prompt eval time = 597.63 ms / 9 tokens ( 66.40 ms per token, 15.06 tokens per second)
llama_print_timings: eval time = 45779.20 ms / 399 runs ( 114.73 ms per token, 8.72 tokens per second)
llama_print_timings: total time = 46466.62 ms / 408 tokensFull run
llama.cpp % ./main -m models/codellama-70b-hf.Q5_K_M.gguf -p "factorial function in java 21" -n 400 -e
Log start
main: build = 2050 (19122117)
main: built with Apple clang version 15.0.0 (clang-1500.1.0.2.5) for arm64-apple-darwin23.3.0
main: seed = 1707071785
llama_model_loader: loaded meta data with 23 key-value pairs and 723 tensors from models/codellama-70b-hf.Q5_K_M.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = codellama_codellama-70b-hf
llama_model_loader: - kv 2: llama.context_length u32 = 16384
llama_model_loader: - kv 3: llama.embedding_length u32 = 8192
llama_model_loader: - kv 4: llama.block_count u32 = 80
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 28672
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 64
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 8
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 10: llama.rope.freq_base f32 = 1000000.000000
llama_model_loader: - kv 11: general.file_type u32 = 17
llama_model_loader: - kv 12: tokenizer.ggml.model str = llama
llama_model_loader: - kv 13: tokenizer.ggml.tokens arr[str,32016] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 14: tokenizer.ggml.scores arr[f32,32016] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 15: tokenizer.ggml.token_type arr[i32,32016] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 16: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 17: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 18: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 19: tokenizer.ggml.padding_token_id u32 = 0
llama_model_loader: - kv 20: tokenizer.ggml.add_bos_token bool = true
llama_model_loader: - kv 21: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 22: general.quantization_version u32 = 2
llama_model_loader: - type f32: 161 tensors
llama_model_loader: - type q5_K: 481 tensors
llama_model_loader: - type q6_K: 81 tensors
llm_load_vocab: mismatch in special tokens definition ( 264/32016 vs 260/32016 ).
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32016
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 16384
llm_load_print_meta: n_embd = 8192
llm_load_print_meta: n_head = 64
llm_load_print_meta: n_head_kv = 8
llm_load_print_meta: n_layer = 80
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 8
llm_load_print_meta: n_embd_k_gqa = 1024
llm_load_print_meta: n_embd_v_gqa = 1024
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: n_ff = 28672
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 1000000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 16384
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: model type = 70B
llm_load_print_meta: model ftype = Q5_K - Medium
llm_load_print_meta: model params = 68.98 B
llm_load_print_meta: model size = 45.40 GiB (5.65 BPW)
llm_load_print_meta: general.name = codellama_codellama-70b-hf
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: PAD token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.55 MiB
ggml_backend_metal_buffer_from_ptr: allocated buffer, size = 36864.00 MiB, offs = 0
ggml_backend_metal_buffer_from_ptr: allocated buffer, size = 9663.92 MiB, offs = 38439534592, (46527.98 / 49152.00)
llm_load_tensors: offloading 80 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 81/81 layers to GPU
llm_load_tensors: Metal buffer size = 46322.72 MiB
llm_load_tensors: CPU buffer size = 171.96 MiB
....................................................................................................
llama_new_context_with_model: n_ctx = 512
llama_new_context_with_model: freq_base = 1000000.0
llama_new_context_with_model: freq_scale = 1
ggml_metal_init: allocating
ggml_metal_init: found device: Apple M2 Ultra
ggml_metal_init: picking default device: Apple M2 Ultra
ggml_metal_init: default.metallib not found, loading from source
ggml_metal_init: GGML_METAL_PATH_RESOURCES = nil
ggml_metal_init: loading '/Users/michaelobrien/wse_github/llama.cpp/ggml-metal.metal'
ggml_metal_init: GPU name: Apple M2 Ultra
ggml_metal_init: GPU family: MTLGPUFamilyApple8 (1008)
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
ggml_metal_init: simdgroup reduction support = true
ggml_metal_init: simdgroup matrix mul. support = true
ggml_metal_init: hasUnifiedMemory = true
ggml_metal_init: recommendedMaxWorkingSetSize = 51539.61 MB
ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 160.00 MiB, (46689.55 / 49152.00)
llama_kv_cache_init: Metal KV buffer size = 160.00 MiB
llama_new_context_with_model: KV self size = 160.00 MiB, K (f16): 80.00 MiB, V (f16): 80.00 MiB
llama_new_context_with_model: CPU input buffer size = 17.01 MiB
ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 0.02 MiB, (46689.56 / 49152.00)
ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 159.52 MiB, (46849.06 / 49152.00)
llama_new_context_with_model: Metal compute buffer size = 159.50 MiB
llama_new_context_with_model: CPU compute buffer size = 17.60 MiB
llama_new_context_with_model: graph splits (measure): 3
system_info: n_threads = 16 / 24 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 |
sampling:
repeat_last_n = 64, repeat_penalty = 1.100, frequency_penalty = 0.000, presence_penalty = 0.000
top_k = 40, tfs_z = 1.000, top_p = 0.950, min_p = 0.050, typical_p = 1.000, temp = 0.800
mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
sampling order:
CFG -> Penalties -> top_k -> tfs_z -> typical_p -> top_p -> min_p -> temp
generate: n_ctx = 512, n_batch = 512, n_predict = 400, n_keep = 0
factorial function in java 2148
factorial function in java 6647
Factorial of a non-negative integer, is multiplication of all integers smaller than or equal to n. For example factorial of 3 is 3*2*1 which is 6.
We have discussed how to compute factorial of large numbers using BigInteger in previous post. In this post we will discuss another way to calculate factorial of large number using java program. This method can be used in programming competitions where memory and time are constraints. We need only print the result so it is not necessary to store complete result.
1) Start from leftmost digit, i = 0
2) Find value of (arr[i]*x + carry)%10 and update carry
3) If current digit becomes 0, then delete that digit from array
4) Decrement size
Following is implementation of above idea.
*/
// A function to multiply x with the number represented by arr[].
// This function uses simple school mathematics for multiplication.
// This function may value of result if the input integer has
// more digits
int multiply(int x, vector<int> &arr) {
int carry = 0; // Initialize carry
// One by one multiply n with individual digits of res[]
for (int i=0; i < arr.size(); i++) {
int prod = arr[i] * x + carry;
// Store last digit of 'prod' in res[]
arr[i] = prod % 10;
// Put rest in carry
carry = prod/10;
}
// Put carry in res and increase result size
while (carry) {
llama_print_timings: load time = 69713.02 ms
llama_print_timings: sample time = 32.47 ms / 400 runs ( 0.08 ms per token, 12320.20 tokens per second)
llama_print_timings: prompt eval time = 597.63 ms / 9 tokens ( 66.40 ms per token, 15.06 tokens per second)
llama_print_timings: eval time = 45779.20 ms / 399 runs ( 114.73 ms per token, 8.72 tokens per second)
llama_print_timings: total time = 46466.62 ms / 408 tokens
ggml_metal_free: deallocating
Log end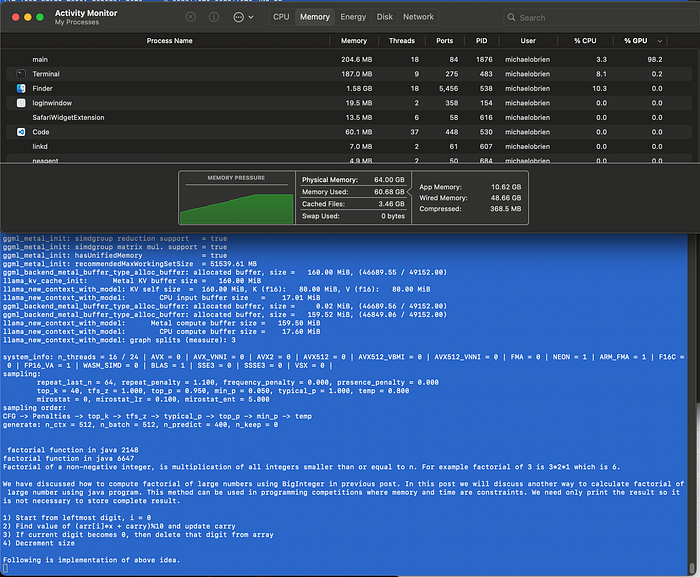
Environment
There are currently two primary GPU environments we can use to work with ML models — The standard Nvidia CUDA 12 and Apple Metal 3 frameworks. Above the hardware we will use TensorFlow 2 which works well with any GPU (Nvidia (Data Center, Quatro or GeForce) or Apple Silicon (M1, M2, M3) as well as CPUs (around 20 times slower).
This article is focused specifically on the Apple M2 Ultra chip in either the Mac Pro or Mac Studio system. The M2 Ultra (or the M1 Ultra) have an 800GB/s bandwidth between GPU and RAM as well as a 2500GB/s interconnect between the 2 dies on an Ultra chip. As an Nvidia reference — the A4500 workstation GA102 GPU has a 640GB/s bandwidth for 20G of VRAM. The consumer RTX-4900 is wider at 1000GB/s
Nvidia has discontinued NVlink between GPUs for all except H100 level data center GPUs and older Ampere Workstation class A4500/A5000/A6000 where 2 A4500 cards are linked by a 112.5 GB/s bridge.
For Nvidia GPU to board RAM the PCIe 4.0 x16 tops out at 32 GB/s
Workarounds
Insufficient VRAM
Models must fit within the available VRAM or the system will enter a sawtooth ram allocation pattern and eventually stop or crash the system. Hence memory size is key — above memory speed or speed/number of streaming processors. For example the following is a failed load of a 25G model in the 21G of usable VRAM in a 32G M1 Max (32 GPU) — https://en.wikipedia.org/wiki/MacBook_Pro_(Apple_silicon)

ggml_backend_metal_buffer_from_ptr: allocated buffer, size = 8021.44 MiB, offs = 16964698112, (24405.50 / 21845.34)ggml_backend_metal_log_allocated_size: warning: curreTry a lower size model like the 7B in this case.
M1Max 32 GPU with 32G
ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 400.00 MiB, (13424.61 / 21845.34)
llama_print_timings: sample time = 36.15 ms / 400 runs ( 0.09 ms per token, 11066.23 tokens per second)
llama_print_timings: prompt eval time = 161.53 ms / 9 tokens ( 17.95 ms per token, 55.72 tokens per second)
llama_print_timings: eval time = 18173.40 ms / 399 runs ( 45.55 ms per token, 21.96 tokens per second)M2Ultra 60 GPU with 64G
ggml_backend_metal_buffer_from_ptr: allocated buffer, size = 13023.86 MiB, (13023.92 / 49152.00)
llama_print_timings: sample time = 33.11 ms / 400 runs ( 0.08 ms per token, 12081.67 tokens per second)
llama_print_timings: prompt eval time = 110.85 ms / 9 tokens ( 12.32 ms per token, 81.19 tokens per second)
llama_print_timings: eval time = 10988.76 ms / 399 runs ( 27.54 ms per token, 36.31 tokens per second)The M2Ultra is 65% faster for eval time than the M1Max with 88% more cores — as expected — however the smaller 32G ram of the M1Max allows for running the model (but with 400GB/s vs 800GB/s memory bandwidth)
Links
Research references:
Google : Transformers — Attention is all you need https://arxiv.org/abs/1706.03762 and https://research.google/pubs/attention-is-all-you-need/
Deep Learning: https://www.deeplearningbook.org/ MIT Press — Ian Goodfellow and Yoshua Bengio and Aaron Courville