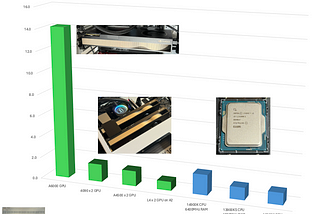
Running reasoning LLMs like the DeepSeek-R1 70b 43G locally for private / offline / air-gapped /…This article details one option towards running LLM inference locally on your private single, double GPU or CPU combination. The focus is…Jan 283Jan 283
Running the larger Google Gemma 7B 35GB LLM for 7x Inference Performance gainTLDR; Run Gemma 7B on a single GPU with over 40 GB VRAM — preferably an 80 GB H100, 40 GB A100 or a 48G RTX-A6000 — performance will be at…Apr 22, 2024Apr 22, 2024
Google Gemma 7B and 2B LLM models are now available to developers as OSS on Hugging FaceOn 21st Feb 2024 Google open sourced the Gemma 7B and 2B LLM models to Hugging Face as OSS. I did some quick testing on these 2 models (10G…Feb 22, 2024Feb 22, 2024
Gemini Advanced is available in Canada as of 17 Feb 2024On 8 Feb 2024 the Google Gemini Ultra 1.0 LLM based app was released worldwide as part of Google Gemini Advanced.Feb 20, 2024Feb 20, 2024
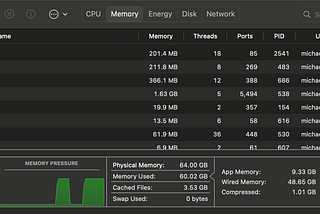
Running the 70B LLaMA 2 LLM locally on Metal via llama.cpp on Mac Studio M2 UltraTLDR; GPU memory size is key to running large LLMs — Apple Silicon because of its unified memory allows for local simulation of…Feb 4, 2024Feb 4, 2024
Testing for Radon 222 radioactive gas levels above 100 Bq/m3 in the home as a result of the…When working remotely during Covid and splitting time between various home office locations that include a basement laboratory — watch…May 29, 2021May 29, 2021